
크롤링을 할 사이트는 네이버 백과 사전(상위5%로 가는 수학교실) 링크 이다.
일반적으로 python으로 크롤링을 하게 되면 Beautiful soup을 사용하는데 requests를 개발한 Kenneth Reitz가 개발하고 있는 requests_html을 사용해보려고 한다.
Kenneth Reitz는 인간을 위한 디자인에 신경을 많이 쓰는 개발자로 이 사람의 손길을 거친 오픈소스는 사용하기가 무척이나 쉽다.
이번 글의 목표는 requests_html의 예제적 목적이 강하다.
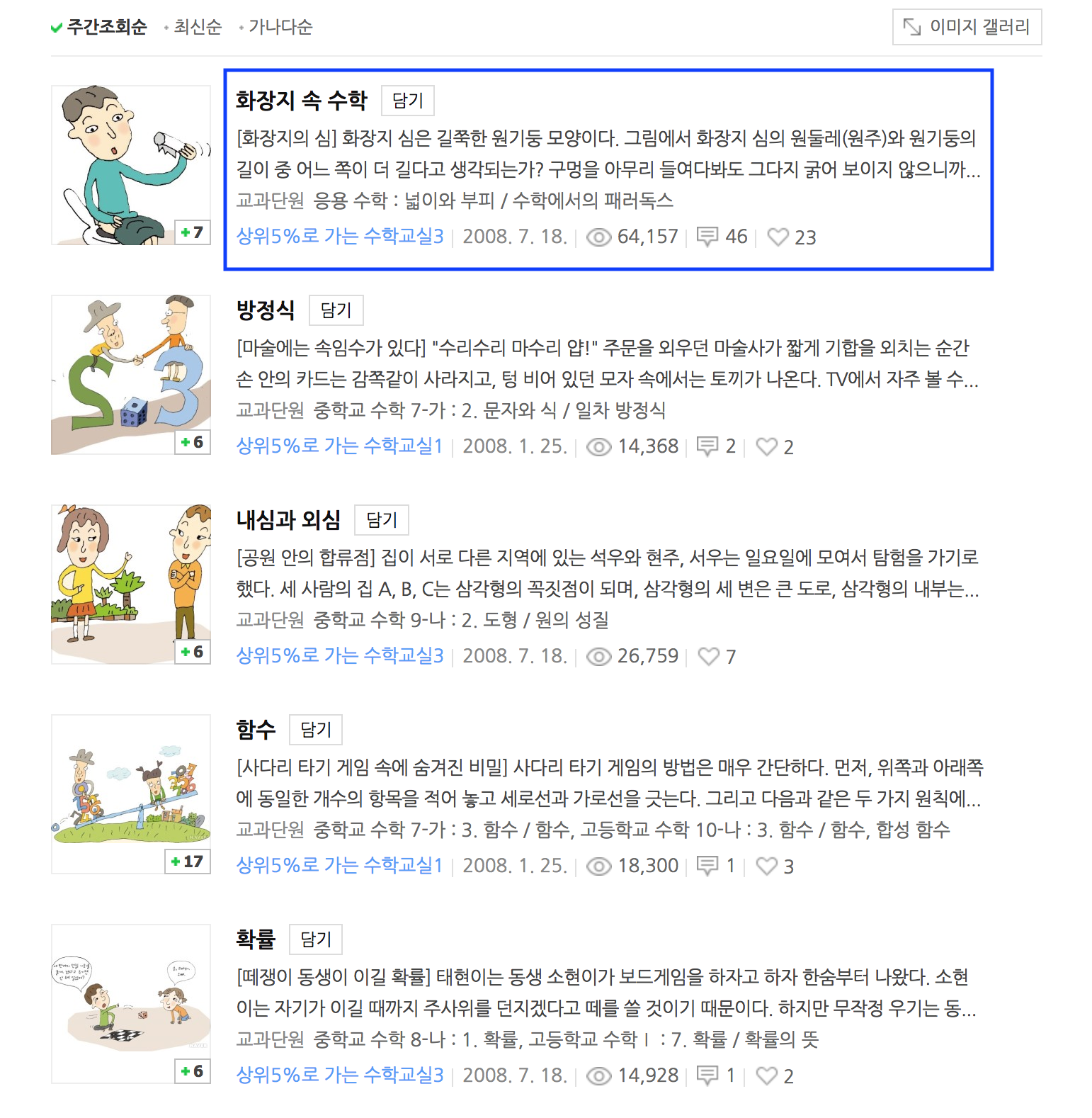
크롤링을 할 데이터는 위의 사진에서 파란 박스 내의 각 제목(화장지 속 수학)과 제목에 걸린 링크들의 리스트를 책 제목을 연결시킨 데이터이다.
아래와 같은 결과를 나오게 할 것이다.
{
'상위5%로 가는 수학교실1': [
{
'title': '화장지 속 수학',
'url': 'https://terms.naver.com/entry.nhn?docId=3387014&cid=58253&categoryId=58325'
}, ....
],
....
}
일단 requests_html을 설치한다. 여기서 주의할 점은 python3.6에만 대응된다는 점이다. 가상환경을 python3.6으로 세팅하자.
pip install requests_html
크롤링할 데이터의 구조를 보면 아래와 같다. 피린섹 원으로 표시한 데이터가 필요한 데이터이다.
각 항목의 구조가 모두 같으로므로 하나에 대응하는 크롤러 코드를 짜고 for문으로 대응해주면 된다.
그리고 페이지가 7까지 있으므로 각 페이지를 모두 크롤해주면 된다. 링

먼저, requests_html에 HTMLSession을 import한다. 크롤링하려는 데이터가 HTML이므로 HTMLSession을 사용한다.
만들어진 HTMLSession 객체에 .get(url) 메소드를 사용하여 HTML 문서를 가져온다.
r.html.find라는 메소드를 사용하여 div에 info_area라는 class를 찾으면,
info_area라는 클래스가 걸린 div 태그들의 Element 오브젝트들의 리스트를 반환한다.
이 리스트들은 ‘휴지 속 수학’, ‘방적식’, ‘내심과 외심’ 등의 데이터를 리스트로 가지고 있다.
# coding: utf-8
from requests_html import HTMLSession
def get_concept_list_per_page():
url = 'https://terms.naver.com/list.nhn?cid=58253&categoryId=58253&page=1'
result = {}
session = HTMLSession()
r = session.get(url)
base = r.html.find('div.info_area') # div class='info_area' 를 모두 찾아라
return result
if __name__ == '__main__':
concept_list = get_concept_list_per_page()
print(concept_list)
base라는 리스트에서 각 항목에 필요한 정보를 가져와야 하므로 for문을 사용한다.
각 항목의 책 제목은 이라는 태그에 들어있으므로 find 메소드를 통해 해당하는 태그를 찾는다.
그런 다음 .text를 사용하면 해당 태그에 있는 텍스트들만을 반환해준다. 이 경우 ‘상위5%로 가는 수학교실3’이 반환된다.
그 다음 title과 url을 찾아오면 각 항목에 대한 대응이 끝난다.
주제의 제목은 div class=’subject’라는 태그 속에 있으므로 find와 text를 통해 간단하게 찾아낼 수 있다.
그다음 url의 경우 동일하게 div class=’subject’에 있지만 a 태그에 href에 값이 존재하기 때문에 text로는 원하는 값을 얻을 수 없다.
이 때 사용할 수 있는 것이 absolute_links이다. 이 메소드는 해당 태그(div class=’subject’) 안에 존재하는 모든 링크를 Set으로 반환한다. set에서는 index를 지원하지 않아서 list로 변환해준다.
div class=’subject’ 안에는 링크가 하나 밖에 없기때문에 [0]을 걸어주면 원하는 link를 얻을 수 있다.
# coding: utf-8
from requests_html import HTMLSession
def get_concept_list_per_page():
url = 'https://terms.naver.com/list.nhn?cid=58253&categoryId=58253&page=1'
result = {}
session = HTMLSession()
r = session.get(url)
base = r.html.find('div.info_area')
for d in base:
title = d.find('span.info.book')[0].text # 책 제목
if not title in result:
result[title] = []
concept = {}
concept['name'] = d.find('div.subject')[0].text # 각 항목의 제목
concept['url'] = list(d.find('div.subject')[0].absolute_links)[0] # 각 항목의 url
result[title].append(concept)
return result
if __name__ == '__main__':
concept_list = get_concept_list_per_page()
print(concept_list)
마지막으로 할 작업은 7 페이지까지 있는 데이터를 모두 긁어와야 하므로 각 페이지별로 크롤링하는 코드를 넣어줘야 한다.
url을 보면 page라는 쿼리스트링으로 페이지를 구분하고 있으므로 page에 1부터 7까지의 값을 주고 각각을 실행하면
모든 페이지에 있는 데이터를 가져 올 수 있다. 최종 코드는 아래와 같다.
# coding: utf-8
from requests_html import HTMLSession
def get_concept_list_per_page():
result = {}
session = HTMLSession()
for i in range(1, 8):
url = f'https://terms.naver.com/list.nhn?cid=58253&categoryId=58253&page={i}'
r = session.get(url)
base = r.html.find('div.info_area')
for d in base:
title = d.find('span.info.book')[0].text
if not title in result:
result[title] = []
concept = {}
concept['name'] = d.find('div.subject')[0].text
concept['url'] = list(d.find('div.subject')[0].absolute_links)[0]
result[title].append(concept)
return result
if __name__ == '__main__':
concept_list = get_concept_list_per_page()
print(concept_list)