
[H3 2011 파이썬으로 클라우드 하고 싶어요_분산기술Lab_하용호] (https://www.slideshare.net/kthcorp/h32011c6pythonandcloud-111205023210phpapp02)
이 글은 윗 링크를 보고 멀티 쓰레드와 멀티 프로세스 부분만을 정리한 글입니다.
일반적으로는 멀티 쓰레딩이 멀티 프로세싱 보다 효율적이다. 멀티 프로세싱을 위해서 프로세스를 더 생성하게 되면 생성되는 프로세스는 기존에 프로세스가 가지는 데이터와 공간을 똑같이 복사하여 가지게 된다. 반면에 쓰레드는 프로세스의 공간 및 자원을 다른 쓰레드와 공유하고 스택만을 따로 가지기때문에 생성되는 시간이 짧으며, 컨텍스트 스위칭이 일어날 때도 프로세스에 비해 오버헤드가 적게 발생한다.
하지만 파이썬에서는 GIL(Global Interpreter Lock)으로 인해 멀티 쓰레딩을 하더라도 싱글 쓰레드보다 속도면에서 이점을 가지기 힘들다. GIL은 자원의 보호를 위해 파이썬 프로그램이 실행될 때 여러개의 쓰레드가 실행되더라도 한번에 하나의 쓰레드만 실행되도록 한다.
이 때문에 파이썬에서 연산부분을 멀티 쓰레딩으로 구현해도 성능 향상을 기대할 수 없다. (I/O, 비동기에서는 활용 가능)
단, GIL은 유저 레벨 쓰레드에만 영향을 미치므로 I/O 등 커널 레벨에서 실행되는 작업의 경우에는 GIL의 영향을 받지 않는다.
from threading import Thread
def work(start, end, result):
total = 0
for i in range(start, end):
total += 1
result.append(total)
return
if __name__ == "__main__":
START, END = 0, 100000000
result = list()
th1 = Thread(target=work, args=(START, END, result))
th1.start()
th1.join()
print(f"Result: {sum(result)}")위의 코드를 싱글 쓰레드로 실행했을 때 걸리는 시간은 7.474이다. (실행시 마다 차이는 있다)
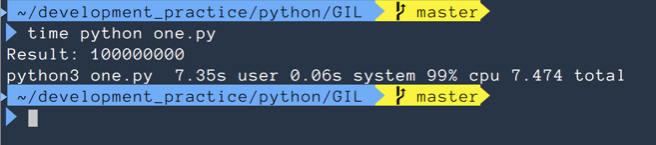
쓰레드를 2개로 늘리면,
from threading import Thread
def work(start, end, result):
total = 0
for i in range(start, end):
total += 1
result.append(total)
return
if __name__ == "__main__":
START, END = 0, 100000000
result = list()
th1 = Thread(target=work, args=(START, END//2, result))
th2 = Thread(target=work, args=(END//2, END, result))
th1.start()
th2.start()
th1.join()
th2.join()
print(f"Result: {sum(result)}")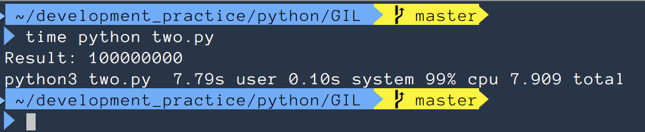
쓰레드 4개
from threading import Thread
def work(start, end, result):
total = 0
for i in range(start, end):
total += 1
result.append(total)
return
if __name__ == "__main__":
START, END = 0, 100000000
result = list()
th1 = Thread(target=work, args=(START, END//4, result))
th2 = Thread(target=work, args=(END//4, END//2, result))
th3 = Thread(target=work, args=(END//2, 3*END//4, result))
th4 = Thread(target=work, args=(3*END//4, END, result))
th1.start()
th2.start()
th3.start()
th4.start()
th1.join()
th2.join()
th3.join()
th4.join()
print(f"Result: {sum(result)}")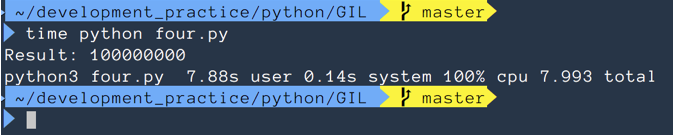
만약 python에서 병렬성을 얻고 싶다면 멀티 프로세싱, GPU, 분산 처리 등을 활용할 수 있다.
그 중 멀티 프로세싱은 쓰레드를 구현하는 방법과 거의 같다.
from multiprocessing import Process, Queue
def work(start, end, result):
total = 0
for i in range(start, end):
total += 1
result.put(total)
return
if __name__ == "__main__":
START, END = 0, 100000000
result = Queue()
pr1 = Process(target=work, args=(START, END//2, result))
pr2 = Process(target=work, args=(END//2, END, result))
pr1.start()
pr2.start()
pr1.join()
pr2.join()
result.put('STOP')
total = 0
while True:
tmp = result.get()
if tmp == 'STOP':
break
else:
total += tmp
print(f"Result: {total}")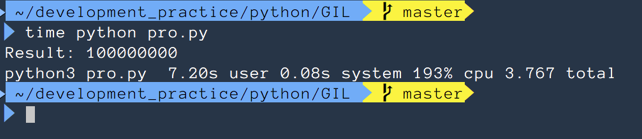
위 코드를 보면 멀티 쓰레딩을 구현할 때와 코드가 거의 유사하다. 결과는 3.767로 병렬적으로 실행된다는 것을 알 수 있다.